CV-인식
1. 딥러닝을 이용한 영상분할
- Semantic segmentation : 모든 pixel에 category label을 label함
: instance를 구분하지 않고 pixel만 신경쓰기에 thing 물체가 여러 개인 경우 구분하지 않고 같 은 category label을 할당
- Instance segmentation : thing 물체만 segmentation하는데 같은 category의 물체가 여러 개면 고유한 번호를 할당해 구 분
- Panoptic segmentation : 모든 pixel에 thing과 stuff 물체 category를 할당하는데 thing 물체는 고유 번호까지 할당해 구 분

1-1. 성능 척도와 데이터셋
segmetation : 밀집 분류문제이며 Pixel Accuracy(PA)로 성능 측정 가능
측정 척도 1) PA
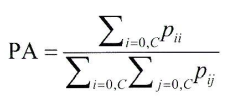
측정 척도 2) MPA

측정 척도 3) IOU
: cateogry별로 AP 계산하고, AP를 모든 부류에 대해 평균하여 mAP를 계산(A,B는 참값과 예측값의 영역)

측정 척도 3) DICE 계수
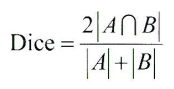

1-2. Semantic Segmentation을 위한 FCN
FCN: convolution 층과 pooling 층으로만 구성된 convolution 신경망
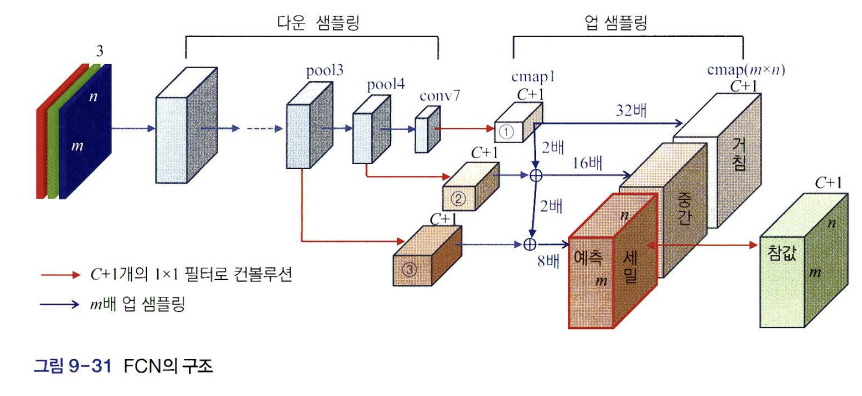
- 입력: m*n 컬러 영상
- 출력: m*n*(C+1) 텐서
- m*n*3크기의 입력영상을 downsampling을 통해 작게 만든 후 다시 m*n으로 키우는 upsampling 거침
- 출력층에서 (j,i) 위치의 C+1개 pixel에 softmax를 적용해 한 pixel은 C+1개 category의 확률을 표현함
- 참값: 데이터셋의 label 정보를 이용해 만듦. m*n*(C+1)로 표현
- 참값 텐서: 모든 같은 위치의 pixel들은 모두 0~2번 맵 중 하나의 맵만 1값을 가지고 나머지 맵은 0값 가짐
- 예측 텐서: 모든 같은 위치의 pixel은 0~2번 맵의 값을 더해 1.0이 됨
ex) (0,0)위치: (0.8, 0.1, 0.1) -> 0번 맵의 확률이 가장 크므로 0을 해당 위치에 기록
- 학습 알고리즘은 예측 텐서와 참값 텐서의 차이인 오류를 줄이는 방향으로 가중치 갱신

Upsampling
- FCN에서는 transpose convolution으로 upsampling을 함
- m*m 특징 맵을 convolution하여 얻은 m'*m'특징 맵에 transpose convoltion을 적용해 m*m 특징 맵으로 upsampling 하는 과정
Transpose convolution 과정

- transpose convolution은 맵의 크기를 복원할 뿐 값을 복원해주지는 않음

FCN 과정
1. input이 pooling, strided convolution을 통해 downsampling을 거친다
2. convolution층이 출력한 feature map에 1*1 커널을 (C+1)개 적용해 category별로 분할 맵을 가진 텐서로 변환
3. 텐서를 skip connection을 이용하며 upsampling을 하여 얻은 cmap, 즉 위의 사진에서 '세밀'이라고 표시한 m*n*(C+1) 텐서를 최종 예측값으로 출력 ( skip connection: 압축하며 소실되는 중요한 정보를 얻기 위해 네트워크가 지나가는 중간중간에 정보를 빼내서 더해줌)
1-3. FCN을 개선한 신경망
DeConvNet
- 오토인코더와 FCN을 결합한 구조
- 오토인코더: 인코더와 디코더가 대칭을 이루는 컨볼류션 신경망

U-net
- skip connection을 평행하게 두고 가운데를 두고 좌우 대칭이 되도록 레이어 배치
- 왼쪽에서 발행한 568*568*64 feature map의 중앙에서 392*392*64만큼 잘라 오른쪽 확대 경로로 전달, 오른쪽에서는 shortcut connection을 통해 전달받은 392*392*64 텐서와 밑에서 올라온 392*392*64 텐서를 이어 붙여 392*392*128 텐서 만듦
- 이 텐서를 convolution층을 통과시켜 최종적으로 388*388*2 분할 맵을 출력
- 분할 맵은 두 장인데 각각 물체 category 확률과 배경 category 확률을 가짐

DeepLabv3+
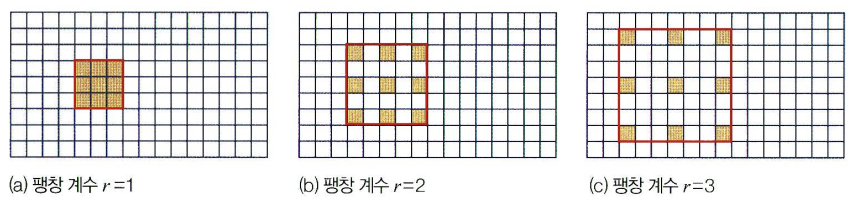
- 인코더에서 상당히 작게 축소했다가 디코더에서 복원하게 되기 떄문에 상세 내용 잃어버릴 가능성이 높은데 이를 dilated convolution(팽창 컨볼루션)을 이용해 누그러뜨림
- dilated convolution(팽창 컨볼루션) : 팽창계수 r을 가짐
2. 사람 인식
1) 얼굴인식
- category가 정해지지 않았으며 그곳을 드나드는 사람이 새로운 category가 되는 zero-shot learning(제로샷 학습)이다.
- 특징 추출 단계 & 매칭 단계
- 응용에 따라 얼굴 확인과 얼굴 식별로 구분
- 얼굴 확인: 두 장의 얼굴 영상이 입력되면 동일인인지 확인하는 문제
- 얼굴 식별: 입력 영상을 등록된 얼굴 영상과 매칭하여 누구인지 알아내는 문제
- 매칭 알고리즘: 두 영상의 유사도를 계산
- 특징 추출 단계: 사전 학습된 convolution 신경망을 백본을 사용해 전이 학습하여 해결 / 같은 부류에 속하는 얼굴 영상 의 유사도는높게 유지하면서 다른 부류에서 발생한 영상의 유사도는 낮게 유지하는 전략에 따라 constrastive 손실함수, triplet 손실함수, cetner 손실함수등이 개발됨
- 현대적인 얼굴 인식 처리 과정

얼굴 검출: 알고리즘으로 얼굴 영역 오려냄
얼굴 정렬: 알고리즘으로 눈, 코, 입, 귀 등의 위치를 알아냄
얼굴 생성: 일대다 증강/다대일 정규화를 적용항 얼굴 영상 생성
2) 성별과 나이 추정
- 나이 추정: 분류보다 회귀 알고리즘으로 해결 ( 12세를 13세로 잘못 분류한 경우는 12세를 60세로 잘못 분류한 경우 와 달리 거의 맞혔다고 판단하는 것이 합리적이라서)

(a) 출력층이 K-1개인 신경망을 사용하는 방식. 각 출력층은 나이가 k이상인가라는 질문을 책임짐
(b) 이진 분류를 담당하는 K-1개 신경망을 사용하는 방식. 각 신경망은 나이가 k이상인가라는 질문을 책임지는 이진 분류기
(c) 입력 영상에 대해 나이 범위를 초기 추정한 다음 정제. 정제한 나이로 새로운 범위를 설정하고 다시 정제하는 과정을 반 복해 정밀한 나이 추정 시도
- 나이 추정의 성능 측정 척도 : 평균절대값오차 / 누적 점수
- 성별 인식
- 성별인식은 비교적 단순한 이진 분류 문제라 다른 과업과 묶어 해결하거나 다른 얼굴 특징과 같이 인식을 시도하는 경우 가 많음