의의 : 배열이 가지고 있는 한계 (배열을 선언할 때 배열이 몇 개의 값을 가질 수 있는지 정의해야하는데 이 때 정의한 배열의 크기를 바꿀 수 없다)를 해결해준다
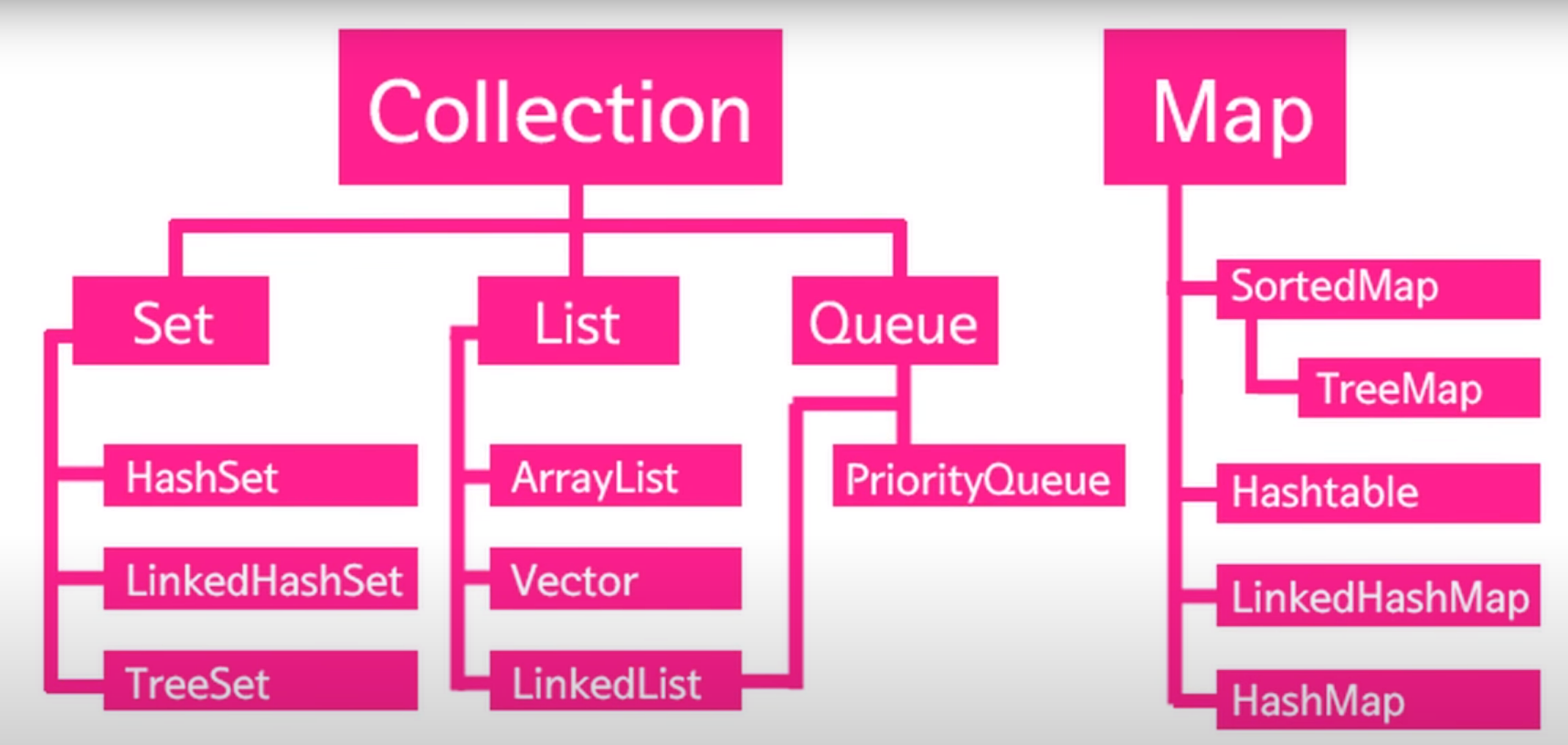
<Collections framework 구성요소>
ex)
- 배열과 비슷하게 작동하나 담을 수 있는 크기에 제한 없는 걸 원하면 List 카테고리 안의 세 가지 중 선택해 사용
- 관리해야하는 데이터가 중복적으로 저장되어 있지 않은 컨테이너를 원하면 Set 카테고리 안의 세 가지 중 선택해 사용 (집합같은 역할)
- key, value 방식의 컨테이너를 원하면 Map 카테고리 선택
Set
-> 고유한 값들만 저장된다 (중복된 값들은 저장되지 않는다)
-> 순서가 존재하 않는다 (뭐가 먼저 나올지 모른다)
-> 그냥 집합이라고 생각하
<HashSet>
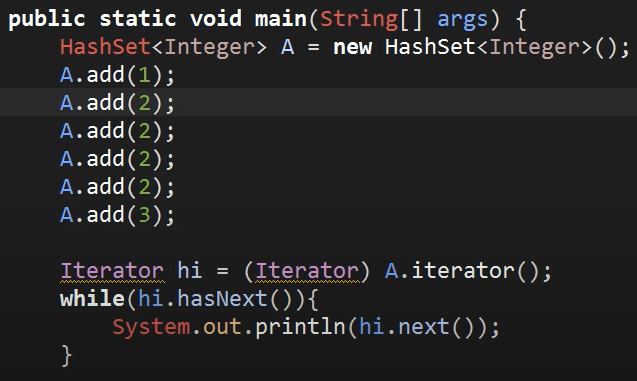
-> 출력 결과

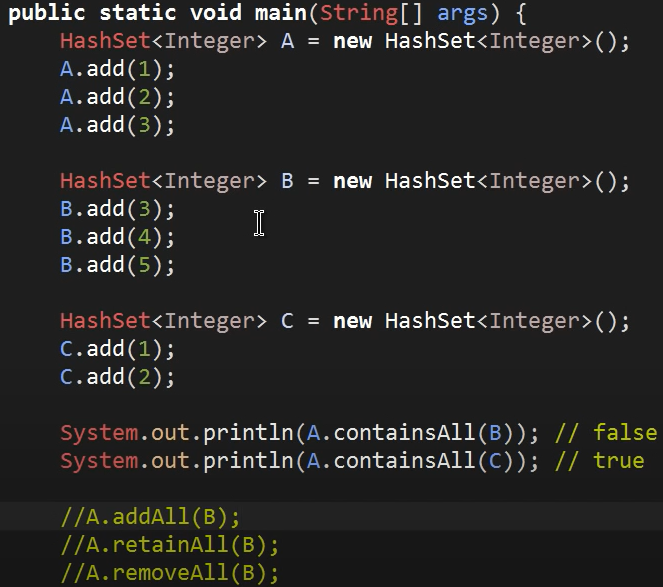
2) containsAll 메소드
A.containsAll(B) : A에 B의 모든 원소가 담겨 있느냐?
3) addAll 메소드
A.addAll(B) : A와 B를 합쳐 A로 만든ek
4) retainAll 메소드
A.retainAll(B) : A와 B 모두에 있는 원소를 A에 담겠다
-> 실행결과, A에는 3만 남게 된
5) removeAll 메소드
A.removeAll(B) : A에 있는 B의 원소들을 제거하라
Iterator
: Collection 인터페이스를 구현하고 있는 모든 클래스들은 iterator 메소드를 통해 반복자라는 것을 제공하도록 강제되어 있다
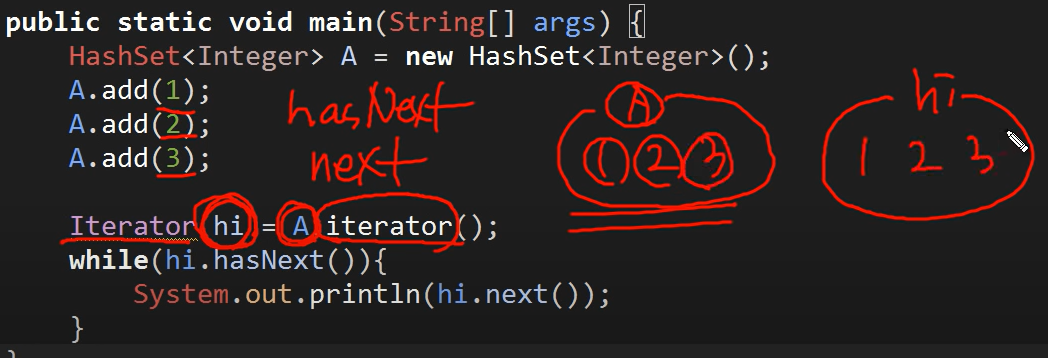
3개의 메소드 가지고 있지만 두 가지가 많이 쓰임
1) hasNext
-> hi 라는 iterator 안에 값들이 존재하는지 확인 (True / False)
2) next
-> hi 안에 들어있는 값들 중 하나를 return하고 hi라는 iterator 안의 해당 값이 사라짐
iterator : 참조값만 가지고 있기에 iterator안의 값이 사라진다고 원본 데이터가 사라지지 않는다
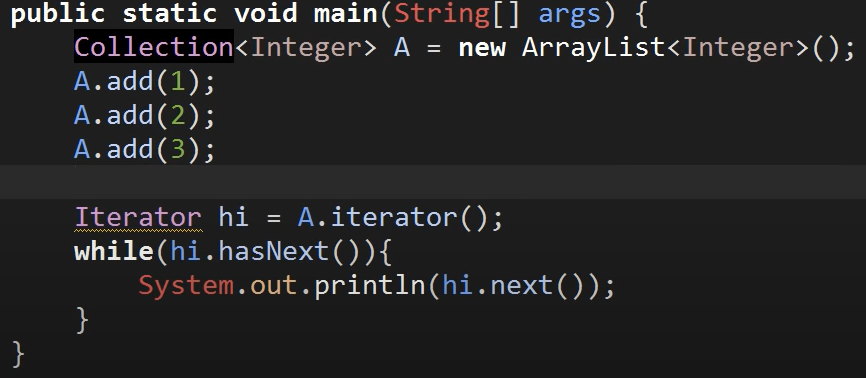
Collection 인터페이스를 구현하고 있는 모든 클래스들은 iterator 메소드를 통해 반복자라는 것을 제공하도록 강제되어 있기에 아래처럼 HashSet에 대한 데이터 타입으로 Collection을 사용해도 된다
-> 이렇게 상위 데이터타입인 Collection을 사용하는 경우가 많은 이유!!!

List
-> 저장하는 모든 것들이 저장된다
1) ArrayList

위 : 배열 / 아래 : ArrayList
ArrayList의 add 메소드 : 어떤 형태의 데이터타입도 수용가능 (인자가 Object형이어야함)
-> 따라서 one이라는 string 데이터 타입은 ArrayList에 저장될 때 Object 데이터 타입으로 저장된다

al.get(i)를 하면 object 데이터 타입을 return 하게 되는데 이를 String타입 변수 value에 저장하려해서 오류가 발생
-> get을 통해 return되는 값을 String 데이터 타입으로 형변환을 해주어야지만 value안에 담을 수 있다

근데 이보다 앞서 배운 제네릭을 활용하는 게 더 좋은 최신 방법!

-> al이라는 ArrayList에 add되는 값(입력되는 값)이 String 데이터 타입이라고 제네릭을 통해 지정해줌!!!
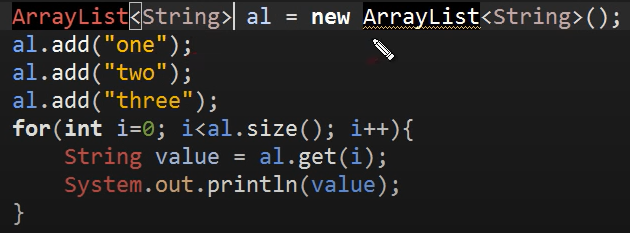
ArrayList 사용 사례

Map
key 값을 컨테이너에게 제공해주면 컨테이너가 그 key값에 해당하 value값을 return 해준다
특징 : List<E> 인터페이스에 비해 요소의 삽입, 삭제, 검색 시간이 매우 빠르다
but, 인덱스로 접근할 수 없어 key로만 접근해야하기 때문에 제약이 있다!

key값은 중복될 수 없지만 value 값은 중복될 수 있다
-> (one,200)이 들어오면 one에 해당하는 value값 1이 200으로 바뀐다
1) HashMap

-> key의 데이터 타입이 String, value의 데이터타입이 Integer
-> put() : Collection 인터페이스에 존재하지 않고 Map 인터페이스에만 존재하는 메소드
-> get() : return 해준다
Map에 있는 값들을 열거하여 반복적으로 처리해주는 방법은 어떻게 될까?!
-> Map은 Collection이 아니기에 iteration기능이 없기에 Set을 만들어 진행한다
( map.keySet() 메소드로 모든 'key'를 Set 컬렉션으로 만든다. 아래 예시에서는 entrySet()이라 칭함)
방법 1) for문

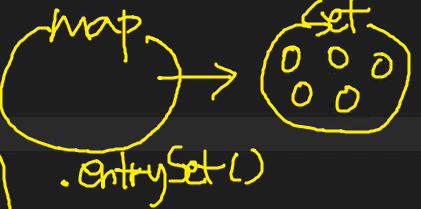
-> Set 안에 들어있는 것 : Map 인터페이스가 가지고 있는 Entry라고 하는 인터페이스를 구현하고 있는 객체가 들어가게 됨
-> Map.Entry 인터페이스에 정의되어있는 메소드 : getKey(), getValue()
-> String : getKey()가 가지고 있는 데이터 타입 / Integer : getValue()가 가지고 있는 데이터 타입
entries 안에 있는 하나하나를 꺼내 entry에 담는다
방법 2) iterator
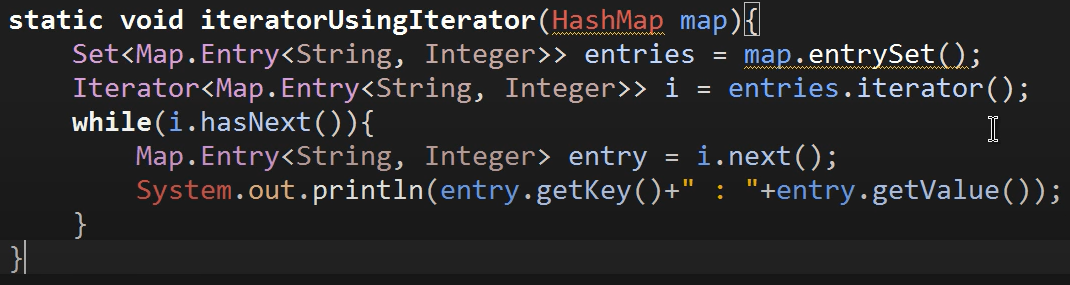
Set 만들어 진행한다는 점은 같으나 Set의 iterator 이용한다
Collection framework에서 정렬하는 방법

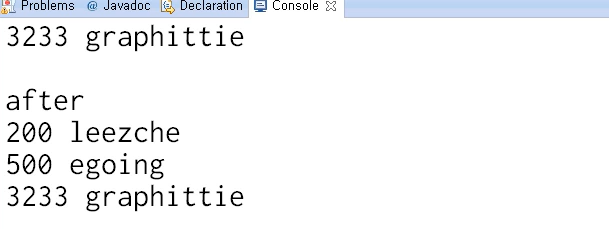
실행결과

-> before : 집어넣은 순서대로 출력된다
-> 이를 500,200,3233 시리얼 값으로 오름차순으로 정렬하고 싶다면 ?!
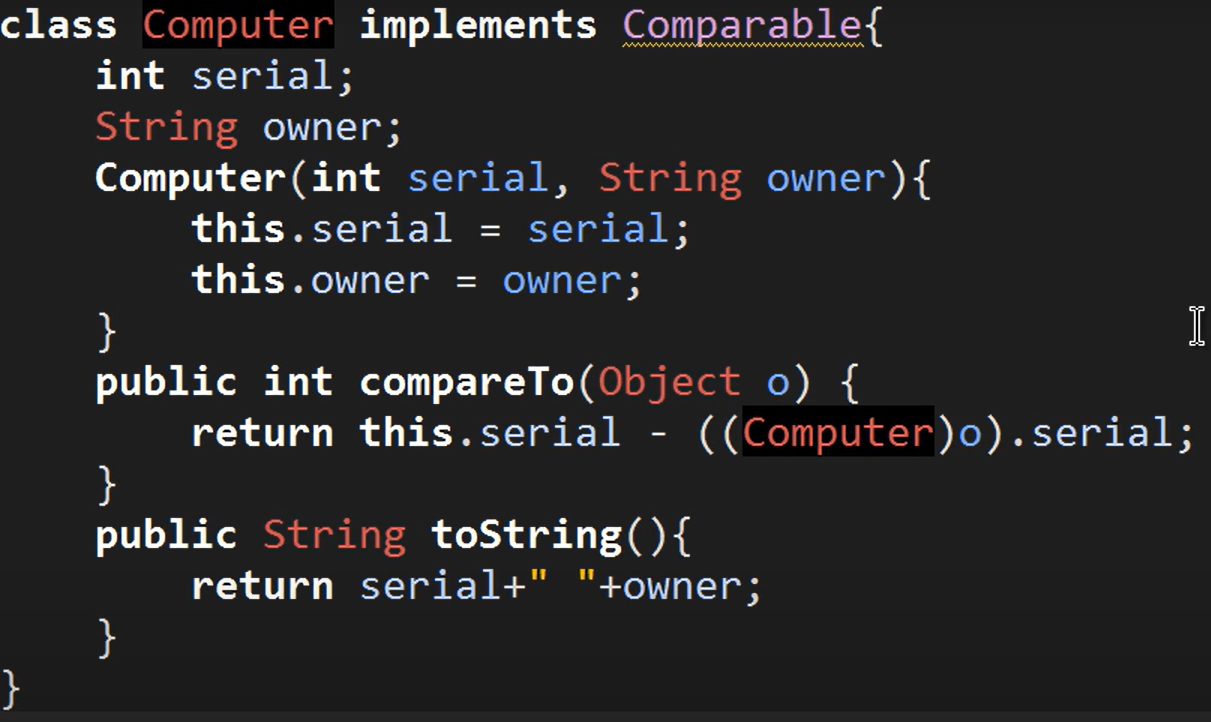
-> Comparable이라는 인터페이스 사용하기!!
정렬 방법을 이해하기 위해 이제 위의 Collections.sort(computers) 부분을 살펴보자
-> Collections는 클래스로, Collection 인터페이스와 다름!!
Collections : 여러 데이터 타입 처리해줌 ex) 정렬
-> Collections가 computers 객체를 정렬해주는 코드
sort 메소드를 자세히 살펴보면

-> sort는 List 형태의 컨테이너만을 정렬해준다는 뜻 + T는 Comparable이라는 인터페이스를 extends, 즉 구현하고 있어야 함
-> list 타입의 컨테이너를 sort 하려면 list의 각 객체들이 Comparable 인터페이스를 구현하고 있어야 한다는 뜻!
-> 그래서 위에서 Computer 클래스가 Comparable을 extends 하고 있었던 것이다!!!
Comparable은 compareTo라는 메소드를 구현하도록 강제됨
실행결과 (정렬됨)