Decision tree에서 어떤 걸 node로 할지 정하는 기준이 뭘까?
-> 어떤 feature를 node로 사용했을 때 homogeneous group이 많이 생성되는지
* homogeneous group이란? -> 같은 label의 멤버들만 contain 하는 그룹
1. 모든 feature를 node로 설정해본 후 각 feature 경우마다 몇 개의 homogeneous group member들이 생성되는지 세보기
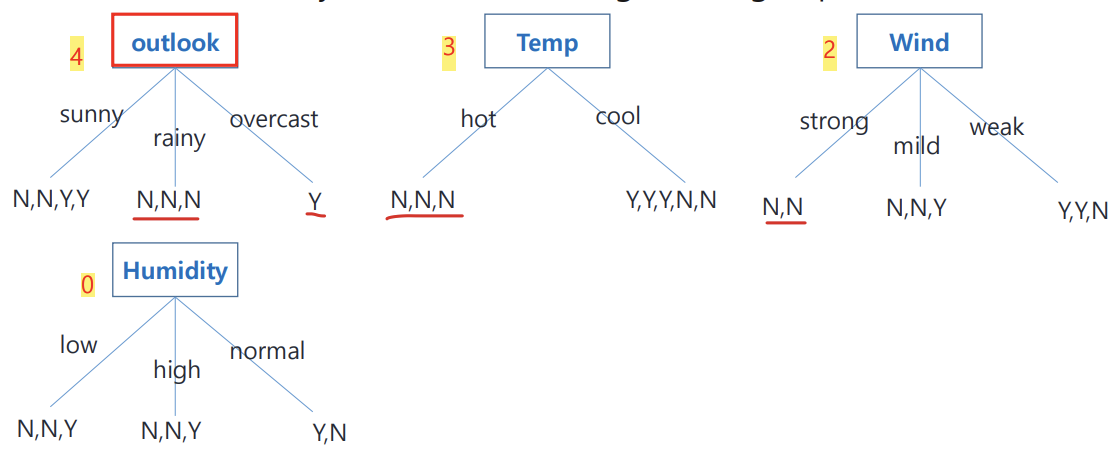
2. 여기서 보면 outlook을 feature로 할 때가 가장 homogeneous group 개수가 많다. 따라서 얘를 node로 하기
위의 outlook의 경우를 보면 sunny일때 N,Y가 섞여있는 impure 상태다.
따라서 트리를 확장해서 더 separate, classification하기
-> 모든 데이터 볼 필요 없이 sunny 데이터만 관찰하기!
-> 그 후 1의 과정을 outlook이 feature일때 제외하고 다 해보기 (이때 data는 전체를 이용하는 게 아니라 sunny인 것만)
-> 3가지 경우 다 해본후 마찬가지로 homogeneous group 개수가 가장 많은 feature를 다음 노드로 선택하기
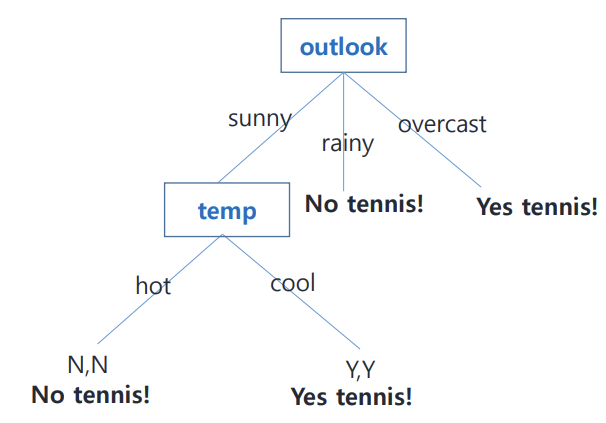
위의 예씨는 깔끔하게 homogeneous하게 떨어짐.
하지만 현실에서 이런 경우는 매우 드물다.
-> 1) 데이터셋이 매우 많아서 homogeneous가 존재하지 않을수도 있고 2) discrete value가 아닌 numerical value 사용할 수도 있다.
-> 다른 방법이 필요
1 해결법 1) Entropy / Information gain
Entropy란? -> 서로 다른 label인 data들이 많이 섞여있을 때 커짐 (0~1의 값을 가진다)
따라서 entropy 값이 클수록 classification 결과가 안좋다.
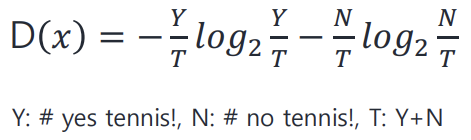
이제 아까했던 테스트를 entropy를 이용해서 해보자
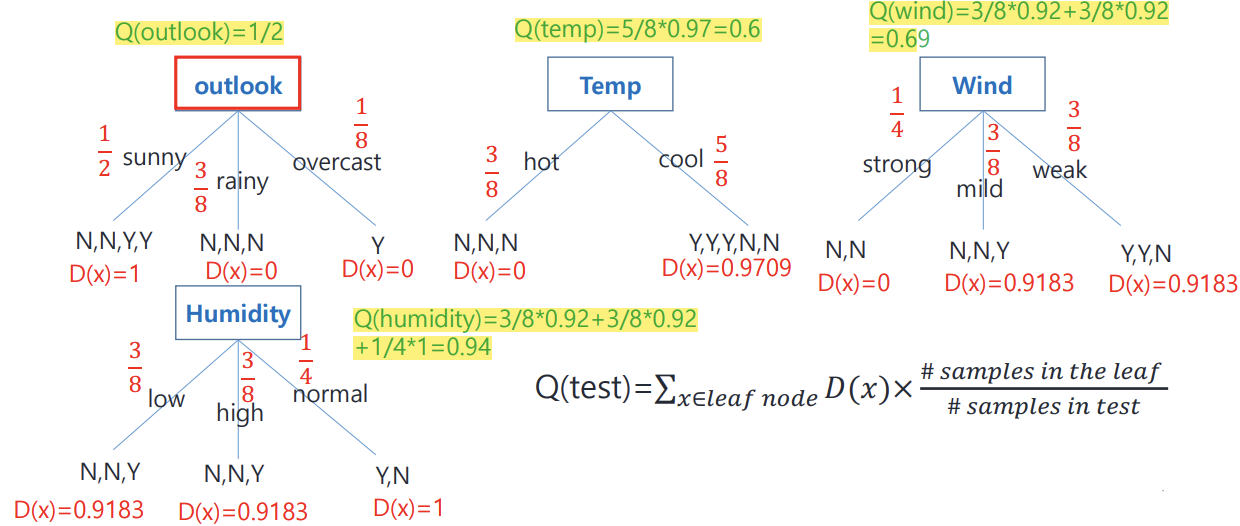
계산된 Q값은 앤트로피를 의미하므로 Q값이 작을수록 불순도가 낮다, 즉 classification 잘한다는 뜻
Q가 작을수록 좋다!
따라서 outlook을 root node로 선택
1 해결법 2) Gini impurity
Gini impurity가 높을수록 해당 노드에서 데이터가 혼잡하거나 다양한 클래스로 이루어져 있다.
-> Gini impurity가 높을수록 안 좋다


Q값 : gini impurity
-> Q값이 가장 작은 애를 feature로 선택하게 된다.
2 해결법)
numerical value handle 하는 방법
1. sort it
2. take average between rows
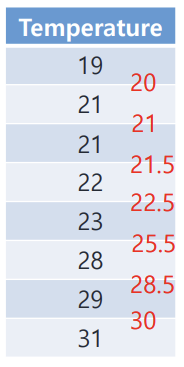
3. 각 평균들을 candidate로 삼아 테스트 해본다

4. entropy / gini impurity 계산해서 가장 작은 Q값 나오는 애를 feature로 고르기
Regression tree
밀집된 class끼리 묶을 때 어떻게 tree 형성되는지
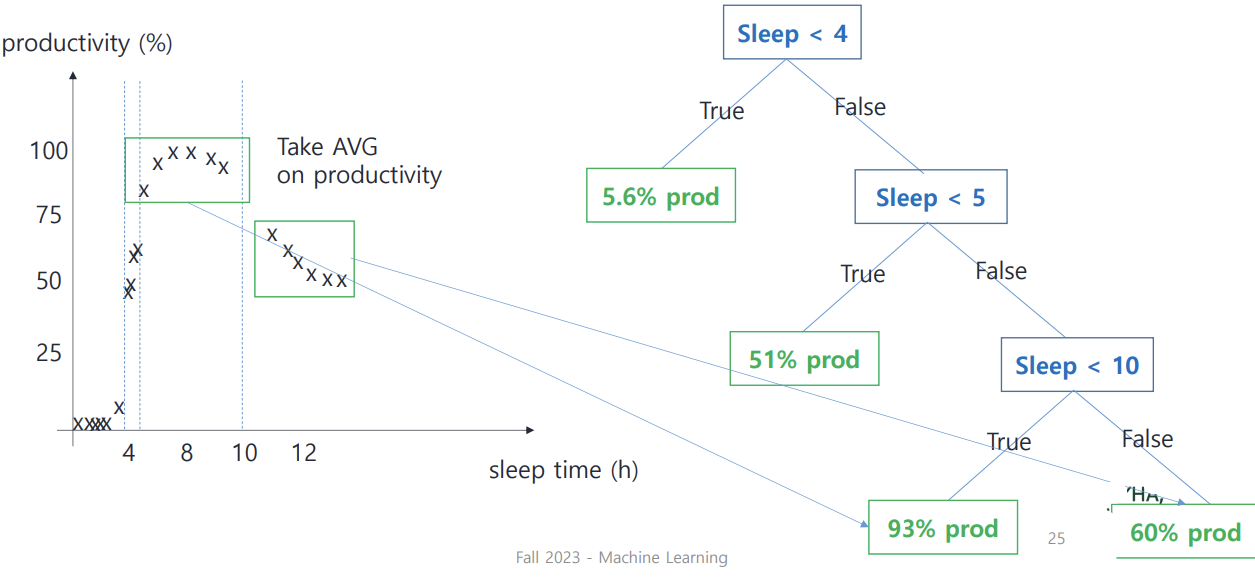
-> 눈으로 봤을 때 밀집된 구간마다 구간 끊어주어(split bar 이용) feature로 설정
하지만 현실에선 이렇게 명확하게 나눠주기 어려운 경우가 많다. 이런 경우는 split bar를 어떻게 넣냐?
-> 모든 data point마다 split bar를 넣어주어 각 split point에서 squared residual 계산한다.
그후 squared residual sum 값이 가장 작은 지점을 선택하기

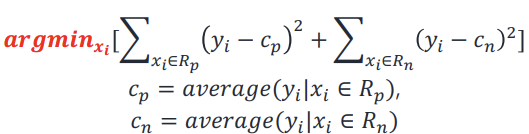
Oscam's razor
Simple tree가 complex tree보다 낫다. tree의 사이즈가 커진다고(node 추가)performance enhance보장 못함.overfitting때문
complex tree는 overfitting 될 수 있기에 pruning(가지치기) 해야한다.
test data의 error rate > train data의 error rate 면 overfitting 이다.
overfitting의 amount= test data error rate - train data error rate
Overfitting 방지법
1. Pre-pruning
-> split point가 statistically insignificant 해지면 tree growing을 멈춘다
2. Post-pruning
-> overfiting 상관없이 tree grow 하다가 pruning 한다.
-> ex) Reduced Error Pruning
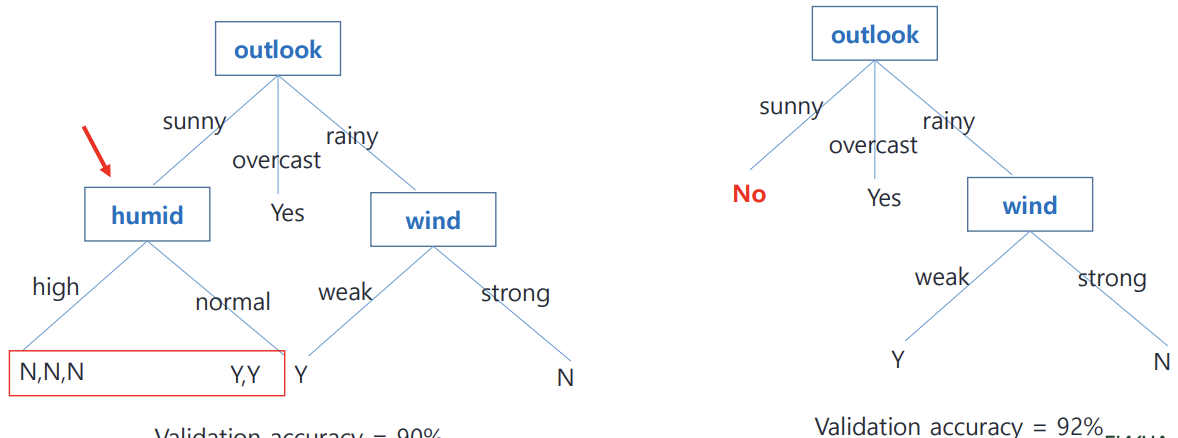
Reduced Error Pruning 방법
1. leaf node부터 탐색해본다. 임의의 노드를 pruning하기전의 validation accuracy 기록해두고 해당 노드를 pruning 해본다.
2, pruning 후의 validation accuracy가 높다면 제대로 pruning 된것이므로 keep하고 계속 이어서 pruning 해나간다. pruning이 harmful 될때까지
'인공지능 > Machine Learning' 카테고리의 다른 글
| Unsupervised - Clustering (0) | 2023.12.12 |
|---|---|
| model assessment (0) | 2023.12.11 |
| Soft margin classifier (0) | 2023.10.25 |
| SVM (Hard margin classifier) (0) | 2023.10.24 |
| Linear Models for Classification (0) | 2023.10.23 |



