Bias-variance tradeoff
model이 too simple -> large bias(small variance) & underfitting
model이 too complex -> large variance(small bias) & overfitting
-> bias와 variance는 tradeoff 관계, 즉 반비례 관계이다!!
따라서 우리는 bias와 variance 사이의 good tradeoff를 나타내는 모델을 선택해야 한다
train / test / validation set splits
data를 train / test / validation set으로 split 해야함
same entire set을 쓰지 않는다
validation set이 필요한 이유?!
- Model selection
- Hyper-parameter tuning
- Early stopping
-> 위의 세 가지 모두 train 단계에 포함되는 과정들이다
model assesment 단계
1. data를 training(60%) / validation(20%) / test(20%) 로 나눈다
2. training set으로 model 훈련시킴
3. validation set으로 최소 error 가지는 best model 선택
4. test set으로 모델 평가
만약 small dataset을 가지고 있다면?! (몇백개)
-> K-fold cross validation 진행한다
-> 각 모델을 Mi라고 하자. dataset을 k개의 pieces들로 나누고 하나의 piece Dj는 test set에 사용하고 나머지는 모두 train에 사용한다
-> 그 결과 hypothesis fij를 얻고
-> Dj로 hypothesis fij를 테스트 함으로써 오차Dj 를 구한다.
-> 모델 Mi의 오차는 오차Dj들의 평균으로 결론 낸다
-> 이렇게 구한 estimated generalization error가 최소인 애를 최종 모델로 선택하고 전체 data set D로 모델 재훈련
시킨다
cf) Leave-one-out cross validation
-> 데이터셋이 100개 미만으로 더욱 작을 때 사용!
-> K-fold cross validation과 마찬가지로 sample 개수에 따라 piece로 나누고 하나의 sample만 test에 이용하고 나머지는 training에 사용하고 average 내서 최종 outcome 도출
Classification metrics
Outcome 4종류 (True:잘분류됨 / False : 잘못 분류됨, positives:positive로 분류됨 / negatives:negative로 분류됨)
1. True positives : positive인데 posiitve로 잘 분류됨
2. True negatives : negative인데 negative로 잘 분류됨
3. False positives : negative인데 positive로 잘못 분류됨
4. False negatives : positive인데 negative로 잘못 분류됨
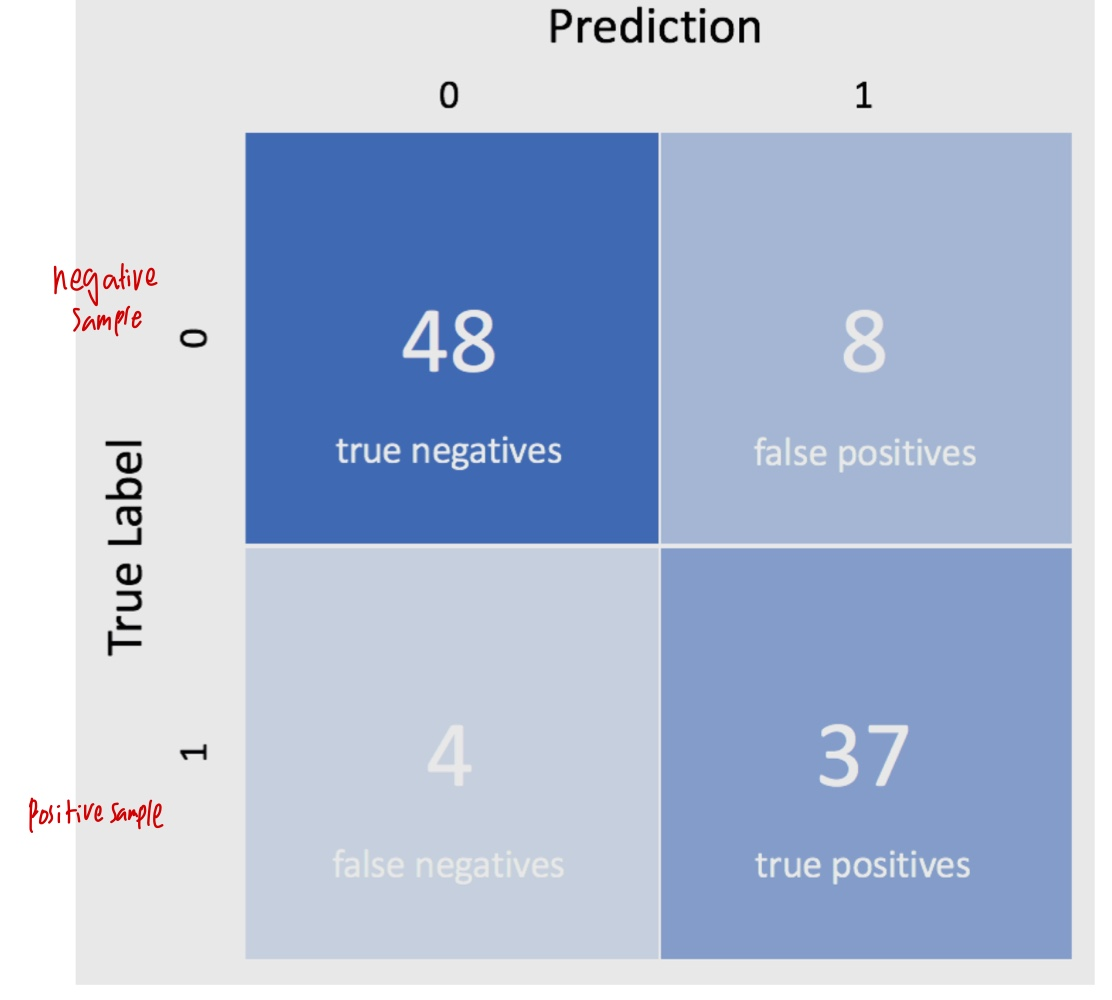
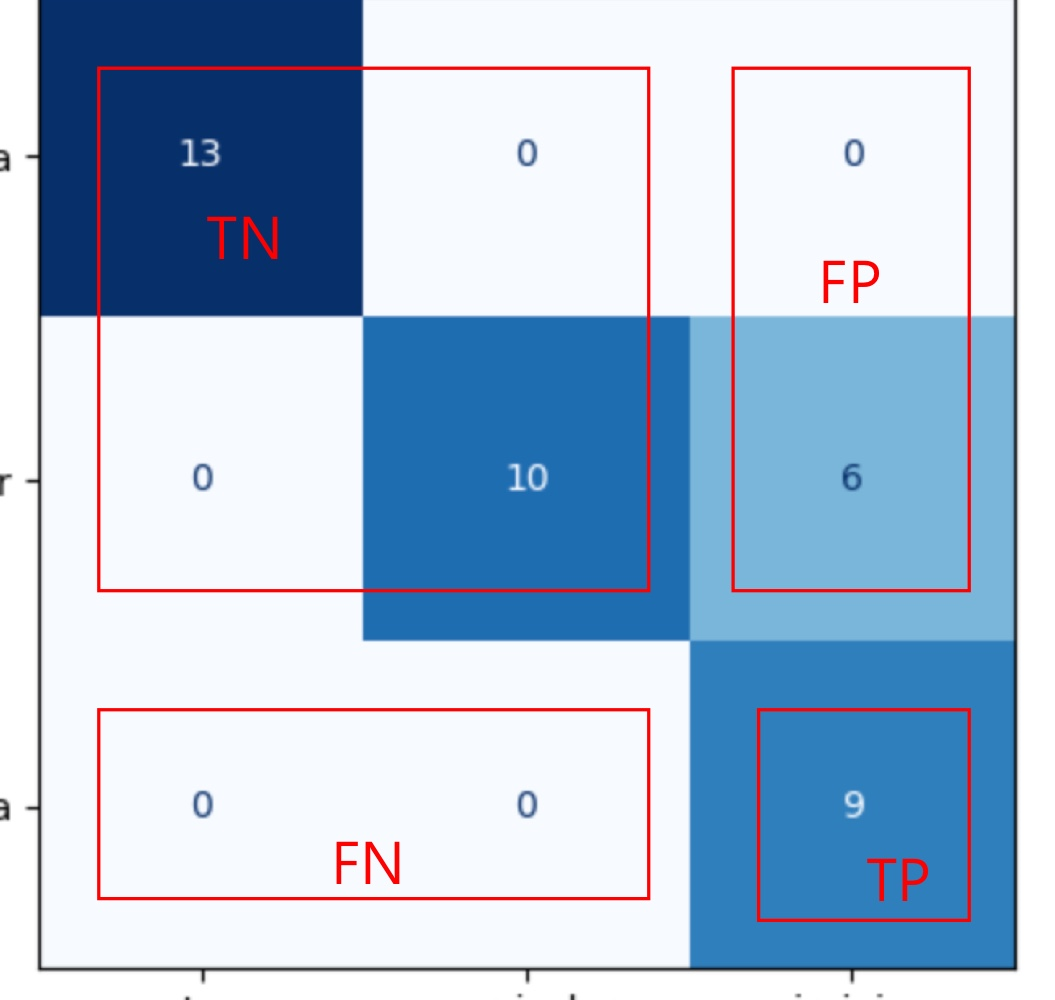
- Accuracy
- = correct / all predictions
- imbalanced dataset에 적절하지 않다
- Precision
- = true positive / (true positives + false positives)
- positive라고 예측한 애들 중에 진짜 positive인 비율 (각 class에 대한 prediction이 얼마나 잘맞는지 보여줌)
- 내 prediciton에 확신을 갖고 싶을 때
- positive class가 얼마나 rare 한지에 의존한다. 따라서 positive class가 negative class보다 interesting할때 사용
- Recall
- =correct true positives / (true positives + false negatives)
- positive인 애들 중에 제대로 positive라고 분류된 비율
- 최대한 많은 positive를 capture하고 싶을 때 사용
-> Precision과 Recall은 tradeoff 관계다!!!
-> imbalanced dataset에서 precision이 recall보다 잘 작동한다
- F1-score
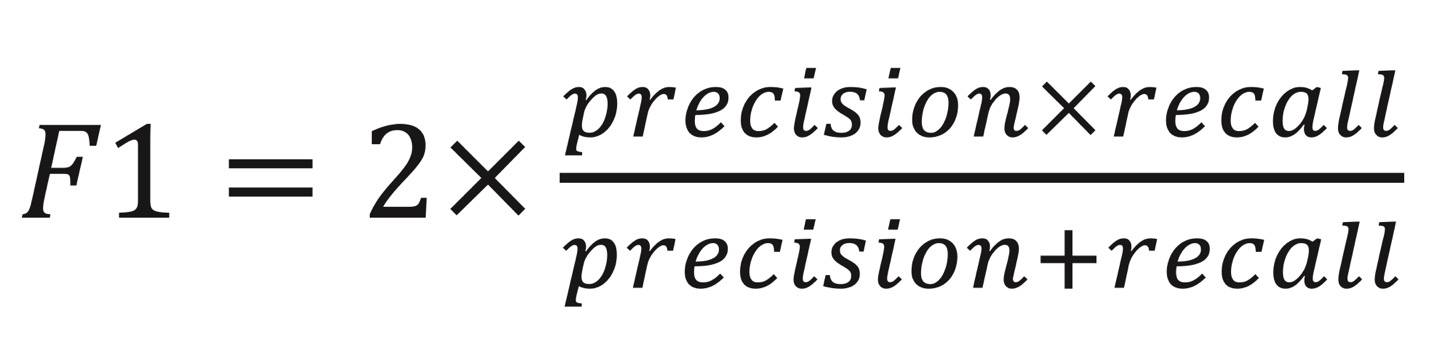
-> precision과 recall 사이에 balance 맞추기 위한 용도
-> model이 good precision & good recall을 가지길 원할 때 사용
-> precision이 increase하면 F1 increase / recall이 increase하면 F1 increase
- Precision-recall curve

- ROC
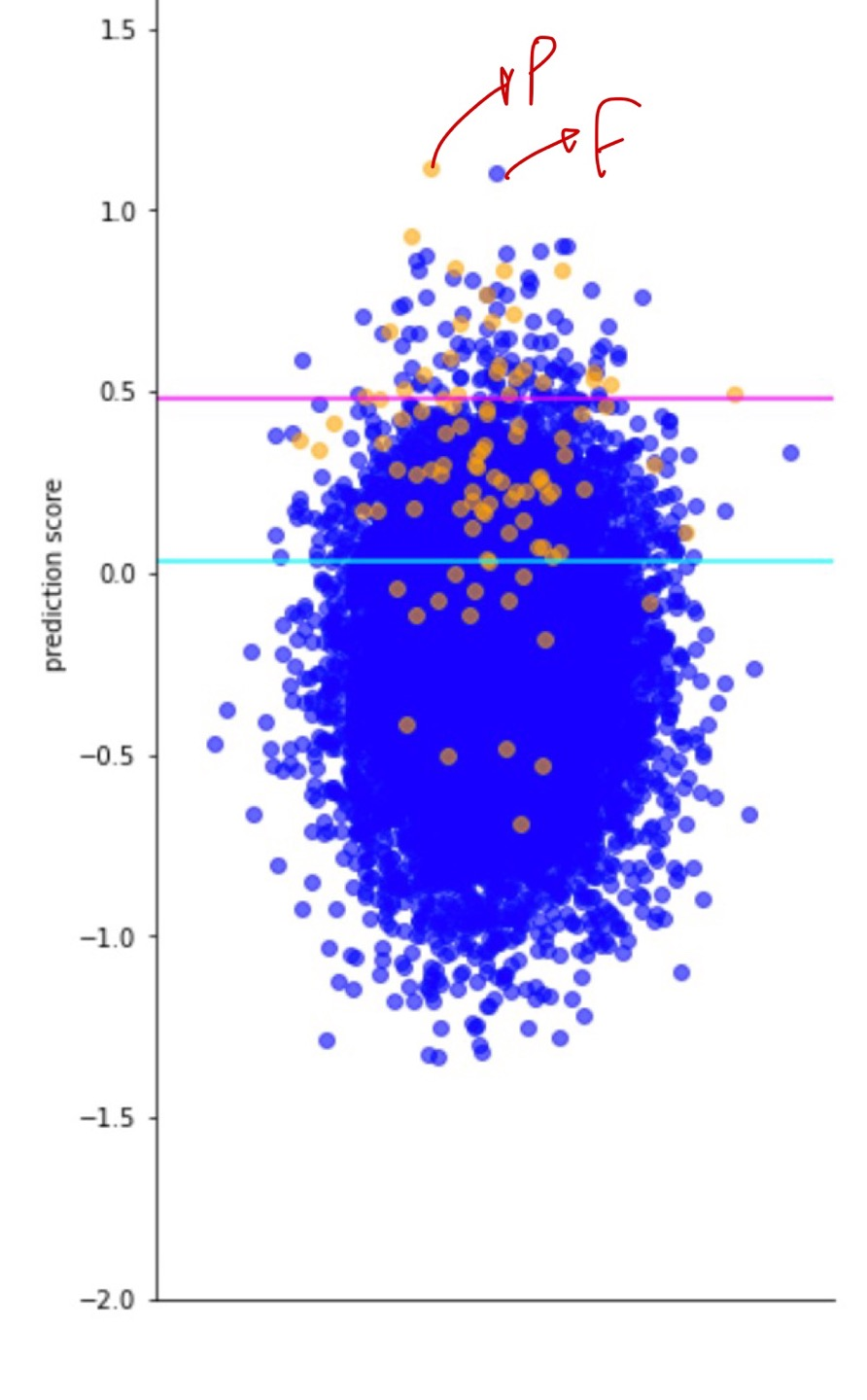
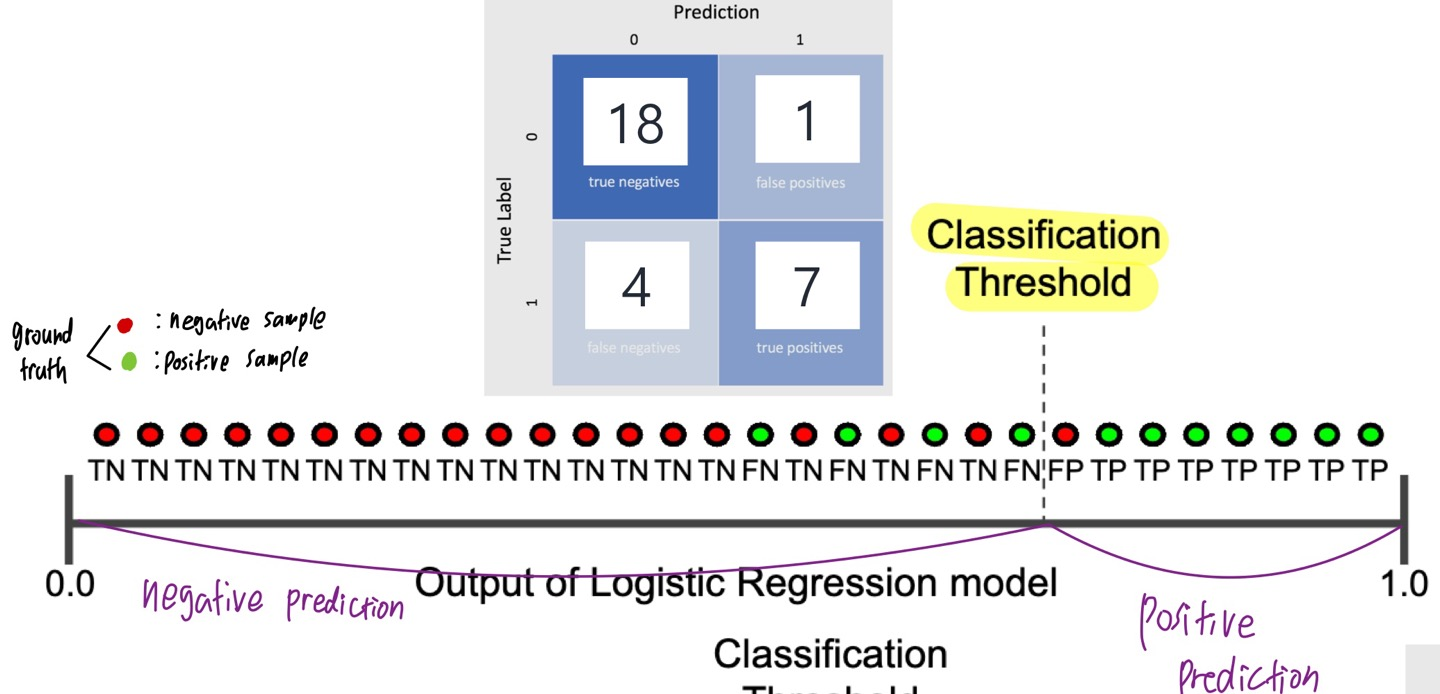
Prediction probability > Classification Threshold : positive prediction이라고 본다
Prediction probability < Classification Threshold : negative prediction이라고 본다
-> 즉 Classification threshold에 따라 prediction result가 달라질 수 있다
'인공지능 > Machine Learning' 카테고리의 다른 글
| Unsupervised learning - PCA (0) | 2023.12.13 |
|---|---|
| Unsupervised - Clustering (0) | 2023.12.12 |
| Decision tree (0) | 2023.10.26 |
| Soft margin classifier (0) | 2023.10.25 |
| SVM (Hard margin classifier) (0) | 2023.10.24 |



